RAG vs. Fine-Tuning: Choosing the Right Approach
for Enterprise LLM Deployment
A practical guide to choosing between RAG and fine-tuning—balancing accuracy, cost, scalability, and governance for real-world enterprise LLM deployments.
Executive Summary
Enterprises adopting LLMs face a critical architectural decision: whether to use Retrieval-Augmented Generation (RAG) or fine-tuning to achieve accuracy and reliability at scale. While RAG enables real-time access to external data and improves explainability, fine-tuning offers deeper model specialization but at higher cost and lower flexibility. The choice is not purely technical—it directly impacts performance, governance, cost structure, and time-to-value.
The goal is to help enterprise leaders design LLM systems that are not only accurate—but also adaptable, cost-efficient, and production-ready.
00
Introduction
Evolution of LLMs in Enterprise AI
LLMs have transitioned from research tools to essential business assets. While early models served general purposes, enterprises now demand industry-specific solutions for finance, healthcare, and manufacturing.
By 2025, Gartner predicts 30% of enterprises will adopt generative AI, up from 5% in 2022, fuelled by advancements in model scalability and customization techniques. This shift underscores the need for strategic approaches to harness LLM potential effectively.
The need for customization in different business scenarios
- Generic LLMs falter with technical jargon, proprietary data, or compliance, requiring customization for fields like finance or healthcare.
- Customization enhances relevance, minimizes errors, and aligns AI with business goals, preventing generic or inefficient solutions.
Key Takeaways
- RAG: Best for dynamic knowledge bases (e.g., customer support, compliance queries)
- Fine-Tuning: Suited for domain-specific fluency (e.g., code generation, legal reports)
- Hybrid: Ideal for complex needs requiring retrieval and refined generation
00
Understanding the Two Approaches
What is Retrieval Augmented Generation (RAG)?
RAG combines a retrieval mechanism with an LLM: it queries a vector database for relevant documents using embeddings, then feeds this context into the LLM to generate informed responses. For example, When asked about new financial regulations, RAG retrieves the latest data and generates a response, ensuring accuracy without modifying the mode
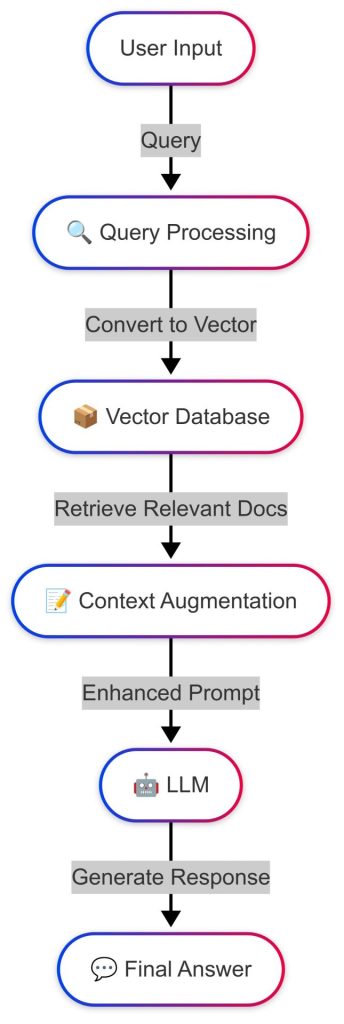
Advantages of RAG
- Real-time updates: RAG integrates fresh data without retraining, ideal for dynamic fields like legal or news.
- Prevents model drift: Maintains accuracy by retrieving external data instead of relying on static knowledge.
- Cost-efficient: Reduces expensive retraining cycles, ensuring scalable enterprise adaptation with minimal overhead.
What is Fine-Tuning?
Fine-Tuning adjusts a pre-trained LLM’s parameters using a curated dataset, such as internal manuals or industry reports, to specialize its responses.
The process involves supervised learning, where the model is trained on labelled examples (e.g., question-answer pairs), refining its understanding of domain-specific patterns.
Example: Fine-tuning GPT-3 on medical records improves clinical term interpretation, embedding expertise directly unlike RAG’s external reliance.
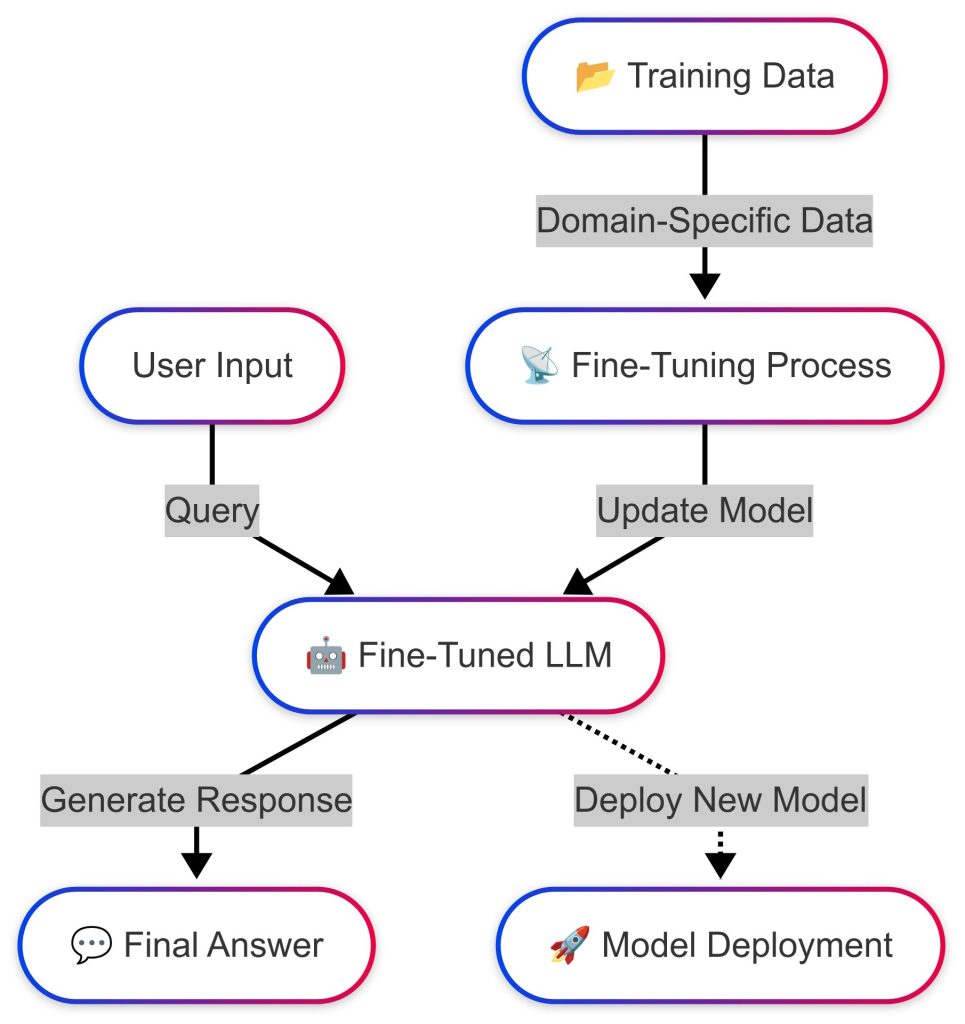
Advantages of Fine-Tuning
- Tailored accuracy: Generates fluent, context-aware responses for tasks like reports or coding (e.g., Python for data science).
- Better coherence: Excels in multi-turn dialogues, unlike RAG, which may struggle with inconsistent data.
- Lower latency: Internalized knowledge reduces dependence on external systems, optimizing structured tasks.
00
Best Use Cases for RAG and Fine-Tuning
RAG Use Cases
- Chatbots for Customer Service: Retrieves real-time FAQs and manuals, ensuring up-to-date responses (e.g., “How do I reset my device?”)
- Technical Support Assistants: Fetches error logs and solutions for IT troubleshooting, scaling across enterprise domains.
- Legal, Compliance, & Finance: Instantly retrieves case law, regulations, or market data for precise, real-time analysis.
Fine-Tuning Use Cases
- Code Generation: Produces context-aware, secure code aligned with organizational standards, improving efficiency
- Creative Content & Reports: Generates summaries, marketing copy, and structured reports while maintaining brand tone.
- Automated Structured Responses: Ensures consistency in customer support, compliance reports, and internal communications
00
Implementing RAG in Enterprise Environments
Core Components of RAG Systems

Vector Database
| Feature | Pinecone | FAISS | Weaviate | Milvus |
|---|---|---|---|---|
| Indexing Speed | High | Medium | High | Medium |
| Scalability | High | Medium | High | High |
| Cost Efficiency | Cloud-based | Open Source | Hybrid | Open Source |
Embedding models for information retrieval
- Domain-Specific Context: Tailored embeddings improve accuracy by understanding industry-specific terms.
- Performance vs. Cost: Complex embeddings boost retrieval but may increase computational costs; balancing both is key.
- Fine-Tuning: Custom-trained embeddings enhance accuracy by incorporating proprietary knowledge.
LLM orchestration for response generation
A robust orchestration layer includes:
- Query Routing: Directs queries to relevant data sources using hybrid search.
- Response Aggregation: Merges retrieved results for consistency.
- Adaptive Caching: Reduces latency and optimizes resource use.
00
RAG vs. Fine-Tuning: Cost, Latency, and Accuracy Comparison
| Aspect | Fine-Tuning | RAG |
|---|---|---|
| Cost | High upfront compute costs for retraining, lower storage costs post-training. Best for static datasets. | Lower training cost, but ongoing expenses for retrieval and storage. Scales well with data volume. |
| Scalability | Needs retraining for new data, leading to downtime and high resource use. | Easily scales with external data updates without retraining. |
| Latency | Faster inference since responses are generated directly. Best for real-time apps with static data. | Slower due to retrieval before generation. Optimized setups reduce lag but remain slightly slower. |
| Accuracy | High accuracy in domain-specific tasks but degrades as data drifts. Requires retraining for updates. | Adapts to changing data by retrieving real-time information, accuracy depends on retrieval quality. |
00
Overcoming Challenges and Next Steps
01. Decision-Making Framework for AI Deployment
Evaluate use case requirements (query type, latency tolerance, data volatility), resource constraints (budget, infrastructure, expertise), and success metrics (accuracy, scalability). Choose a model, ensuring alignment with business goals through iterative testing.
02. Future-Proofing Enterprise AI
Adopt modular architecture, incremental learning, model-agnostic systems, and feedback loops to enable continuous adaptation without major overhauls. Real-time updates keep AI relevant as technology evolves.
03. Cost-Effective & Scalable LLM Deployment
Optimize resource use, integrate open-source tools, automate maintenance, and scale horizontally. Pilot deployments and refine configurations to balance cost and performance efficiently.
00
V2Solutions: Transforming AI Strategy for Enterprises
We lead the AI revolution by delivering tailored large language model solutions that meet specific business requirements. We optimize performance metrics while balancing costs for enterprise applications. From improving customer service to simplifying compliance processes and automating technical tasks, V2Solutions offers innovative AI systems that prepare businesses for ongoing digital evolution. Their customized methodology allows companies to maximize generative AI benefits while prioritizing security and operational excellence.
Discover the right AI strategy for your enterprise—Connect with V2Solutions to get started!
00
Discover the right AI strategy for your enterprise—Connect with V2Solutions to get started
Design the right LLM architecture based on your data, use case, and scalability needs.